
Is Your Computer "Thinking"? Demystifying the Black Magic of Machine Learning.

My grandmother, bless her heart, always said, “Keep Learning." She'd tell stories of learning to bake by trial and error, adjusting ingredients based on how the last cake turned out. She never had a recipe that told her exactly how much flour to use for every single tortilla; she learned from the data of her past attempts.
This concept of learning from experience, of adapting based on what you’ve observed, is remarkably similar to the core idea behind machine learning. It’s not about giving a computer a rigid set of instructions for every conceivable situation. It's giving them the power to find patterns and make predictions based on that.
What Does the Computer Actually Do?
When we talk about ML, particularly "learning from data," the computer's role shifts from a instruction-follower to a pattern-detector. Imagine you want a computer to identify cats in photographs. Instead of writing millions of lines of code to describe every possible shape, color, and size a cat could be, you show the computer a whole buncha pictures. Some pictures contain cats, and some do not. You also tell the computer, for each picture, whether it contains a cat or not.
What the computer does is analyze these images. It doesn't "see" in the way humans do, but it processes the pixels. Through various algorithms, it identifies common features and relationships within the images labeled as "cat" that are different from those labeled as "not cat." It might learn that certain combinations of edges, textures, and colors often indicate the presence of a cat's fur, eyes, or whiskers. It basically just builds a mathematical model based on this experience.
Once this model is built, you can then show the computer a new picture its never seen before. Based on the patterns it learned from, the model will then make a prediction: "This is cat," or "This no cat," along with a level of confidence. This process is often refined over time; if the computer makes a mistake, that feedback can be used to further improve its model.

Is the Computer Thinking?
This is a deep question, and the answer depends on how one defines "thinking." In the traditional human sense of consciousness, self-awareness, and intentionality, no, I, personally, don't think computers are "thinking." It doesn't have emotions, desires, or a subjective experience of the world.
What it is doing is performing complex calculations and pattern recognition at an astonishing speed. It's running algorithms that allow it to identify relationships within data that would be impossible for a human to do manually. When a ML model identifies a cat, it's not contemplating the feline nature of the creature; it's applying a statistical equation to classify the image. While the results can appear intelligent, the underlying mechanism is still mathematical and computational.
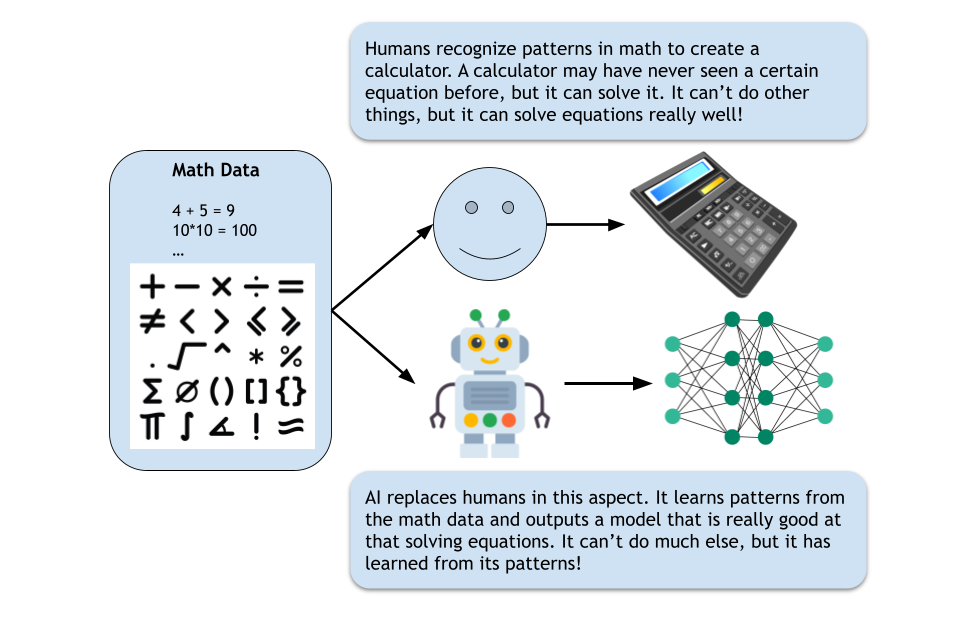
Can It Do Other Things Than What You Teach It?
Generally, no, not directly. A ML model is typically trained for a specific task. If you train a model to identify cats in images, it cannot then write a compelling novel, translate a language, or diagnose a medical condition without further, distinct training. Its "knowledge" is highly specialized and confined to the domain of the data it was trained on.
However, there's a nuanced aspect to this, particularly with advancements in areas like "transfer learning" and "large language models." In transfer learning, a model trained on a very large dataset for one general task (like recognizing many different objects in images) can then be fine-tuned with a smaller dataset for a more specific, related task (like identifying specific breeds of dogs). The general knowledge gained from the initial training acts as a foundation.

Similarly, large language models, trained on vast amounts of text data from the internet, can generate human-like text, answer questions, summarize documents, and even write code. While they weren't explicitly "taught" to do every single one of these things, their extensive training on diverse text allows them to identify patterns and generate coherent responses across a wide range of linguistic tasks. Even in these cases, their capabilities are still bounded by the scope and nature of their training data. They don't suddenly gain the ability to perform physical tasks or engage in completely unrelated intellectual endeavors.
How Expensive Is It?
The cost of machine learning can vary dramatically, from relatively inexpensive to incredibly high, depending on several factors:
- Data Acquisition and Preparation: Gathering, cleaning, and labeling large datasets can be very time-consuming and expensive. If you need specialized data, like medical images or proprietary financial data, the costs can escalate significantly.
- Computational Resources: Training complex machine learning models, especially deep learning models, requires substantial computational power. This often means using powerful Graphics Processing Units (GPUs) or even specialized AI accelerators. You might pay for cloud computing services (like AWS, Google Cloud, or Azure) on a per-hour basis, or invest in your own hardware. For very large models, these costs can run into millions of dollars.
- Talent: Skilled machine learning engineers, data scientists, and AI researchers are in high demand, and their salaries reflect that. Building and maintaining these systems requires specialized expertise.
- Software and Tools: While many machine learning libraries and frameworks are open-source (like TensorFlow and PyTorch), there can be costs associated with commercial software, platforms, or specialized tools.
- Ongoing Maintenance and Monitoring: Machine learning models are not a "set it and forget it" solution. They often need to be retrained as new data becomes available or as the underlying patterns in the world change. Monitoring their performance and addressing biases or drift adds to the ongoing cost.
For small projects or learning purposes, you can often get started with open-source tools and free tiers of cloud services for very little cost. However, for real-world, large-scale applications, the investment can be substantial.
Is This All Super Complicated and Super Mathy?
Yes, at its core, machine learning is indeed "super mathy" and can be quite complicated, especially when you jump into the theory and algorithms. It relies heavily on concepts from linear algebra, calculus, probability, and statistics. Understanding how algorithms like neural networks, support vector machines, or decision trees actually work requires ❇️math❇️.
However, this doesn't mean that everyone who uses or benefits from machine learning needs to be a mathematics Ph.D. The field has evolved significantly, with powerful libraries and frameworks that abstract away much of the low-level ❇️math❇️. Data scientists and developers (me especially) can often use these tools to build and deploy machine learning models without needing to implement the algorithms from scratch.
It's similar to driving a car: you don't need to be an automotive engineer to drive effectively. You need to understand how to operate the vehicle and follow traffic laws.
For those who want to innovate and create new algorithms, a deep mathematical understanding is essential. For many others, a solid conceptual understanding coupled with practical programming skills is sufficient.
In essence, machine learning is about empowering computers to learn from the vast oceans of data we generate daily. It’s a powerful paradigm shift from explicitly programming every action to enabling systems that can adapt and improve with experience. It’s not about creating conscious machines, but about building intelligent tools that can augment human capabilities and solve complex problems.
What aspects of machine learning fascinate you the most, and what real-world applications have you seen that truly impress you? Share your thoughts in the comments below!
If you gotten this far in this very long post, I want to say thank you for reading! You are a very curious reader! 😄

Comments ()